A ConvNet for the 2020s
Context
- This paper was published shortly after the hype explosion around vision transformers (mainly the vanilla ViT and the Swin Transformer) as an alternative to convolutional networks.
Takeaways
-
A “modernized” ResNet (named ConvNeXt) can perform equally or superiorly to ViTs.
-
The ConvNeXt also performed as well as ViTs when pre-trained on large datasets, which challenges the view that ViTs are better at scaling up.
-
In general, CNNs have a more straightforward design (less specilized modules) and do not use the global attention mechanism, which has a quadratic complexity dependency on the input size.
- Proposed modifications to the ResNet architecture:
- Change the number of blocks per stage to (3, 3, 9, 3). Originally it was (3, 4, 6, 3).
- Use a 4 x 4 convolution with stride 4 (non-overlapping convolution) as the ResNet stem cell.
- Use grouped convolutions (a là ResNext), more specifically, depthwise convolutions, in the first layer of the block.
- Use larger convolutions — 7 x 7 instead of 3 x 3.
- Restructure the block as an inverted bottleneck: a layer with many filters sandwiched between two layers with fewer filters.
- Use just one activation function per block and replace the ReLU with GELU.
- Use layer norm instead of batch norm.
- Insert spatial downsampling layers (2 x 2 conv with stride 2) and normalization layers between each stage.
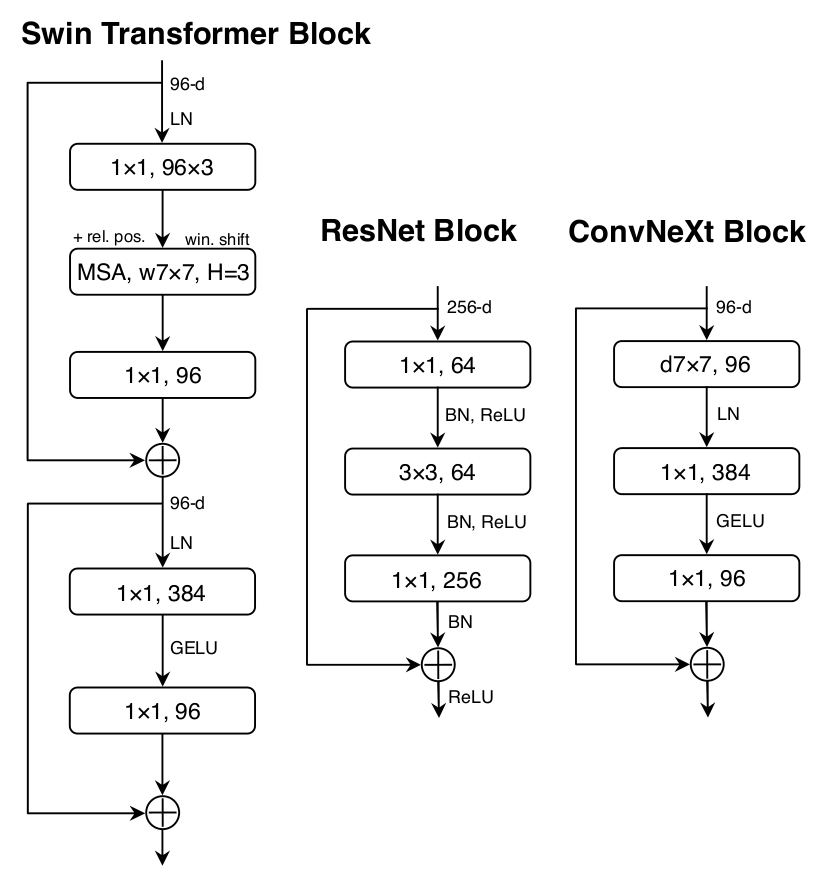
- The figure above (taken from the paper) shows the ConvNeXt block compared to the ResNet’s and the Swin Transformer’s.
- The training recipe was also modified:
- 300 epochs instead of 90.
- AdamW optimizer.
- Learning rate linear warm-up followed by a cosine decay.
- Data augmentation: mixup, cutmix, randaugment, and random erasing.
- Regularization with stochastic depth and label smoothing.