Self-training with Noisy Student improves ImageNet classification
Takeaways
-
The paper proposes a semi-supervised technique named “Noisy Student Self-learning.” It is meant to be used when large amounts of unlabeled data is available in addition to a the labeled dataset.
-
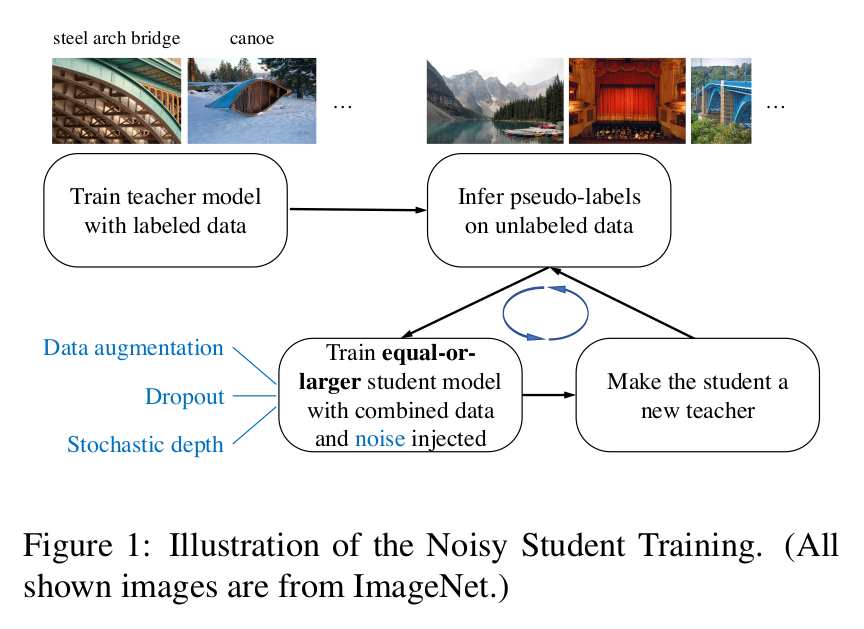
It is a iterative process (see figure above). First a model is trained solely on the labeled data. Then this model takes the position of a “teacher” and is used to generate pseudo-labels for the unlabeled dataset. Next, a “student” model is trained on the union of the labeled and pseudo-labeled datasets. Most importantly, the student training should be noised (they used dropout, stochastic depth, and data augmentation). Finally, the student becomes a teacher, relabels the unlabeled dataset, and a new student is trained. They repeated this cycle three times.
-
Dataset relabeling is done without noise.
-
Noise while training is vital. The conditions for learning have to be harder than the conditions for generating the labels. This is what allows the student to surpass the teacher. Data noise forces the student to learn predictions invariant to augmented instances of the images. And model noise forces the student to mimic an essemble decision maker (the complete teacher) with only a fraction of its model.
-
The student can be larger or as large as the teacher. There is a small benefit in using larger students, but using models of the same size works well too.
-
It is better to train jointly on the labeled and pseudo-labeled dataset, than to do it first on the labeled than on the pseudo-labeled.
-
The more unlabeled data the better.