Revisiting Self-Supervised Visual Representation Learning
Takeaways
-
The paper presents a large empirical study comparing different self-supervised techniques and neural architectures (all CNNs; this is a 2019 paper).
-
Increasing the number of filters consistently improves performance. This is similar in the fully-suppervised scenario. But in self-supervising the effect is even more pronounced. Accuracy improvements were observed even in the low-data regime.
-
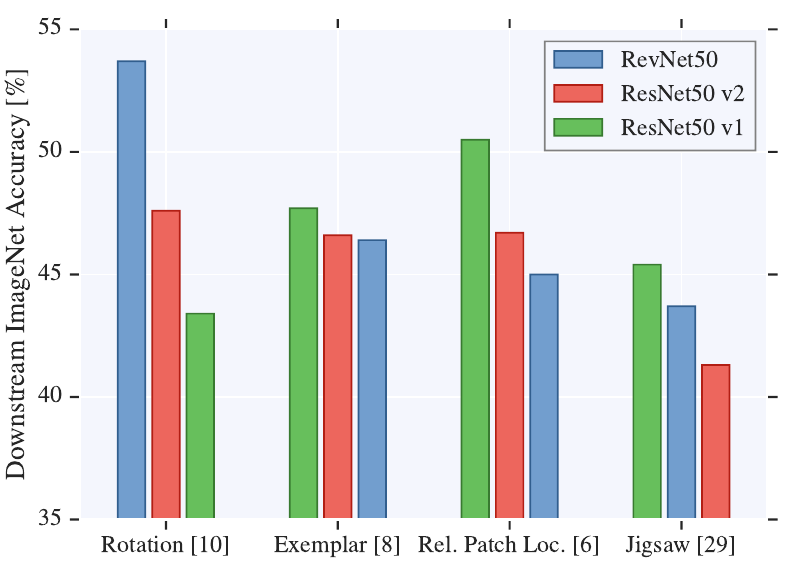
Overall, the performance on the pretext task is not predictive of the performace on the downstream task.
-
For ResNets, the downstream accuracy is higher when using the representations obtained from the last layer (the one before the “logits layer”, which, in turn, is task-specific).
-
On the downstream task, an MLP performed just marginally better than a simple linear classifier (logistic regression).
-
Training the logistic regression to convergence can take a lot of epochs. They saw improvements even after 500 epochs.