Barlow Twins: Self-Supervised Learning via Redundancy Reduction
Takeaways
-
The paper proposes a new loss function for self-supervised learning.
-
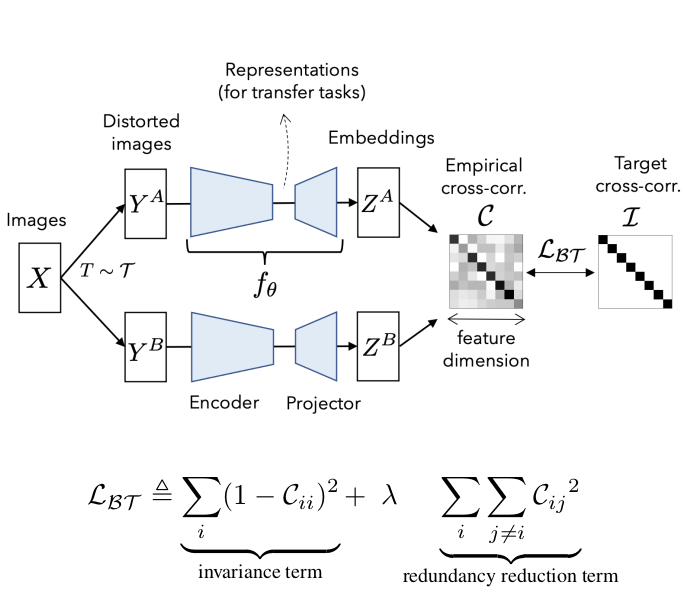
It is based on the cross-correlation matrix (CCM) of the outputs of two identical networks fed with two distorted versions of the same image. See the image above.
-
The loss value is minimal when the CCM is equal to the identity.
-
Having the CCM’s main diagonal elements equal one means that the network outputs are invariant to each other. Therefore invariant to the distortions.
-
Having the off-diagonal elements equal zero means that the output dimensions are uncorrelated. Therefore the information redundancy is zero. This constraint avoids the training collapse (i.e., when the network ignores the inputs and always outputs a constant prediction.)
-
Barlow Twins are very simple and easy to implement. Still, it performs competitively or outperforms other state-of-art methods.